
Project By: Krishna Adatrao
Evaluation: Tata Consultancy Services
ABSTRACT
The rapidly increasing quantity of publicly available videos has driven research into developing automatic tools for indexing, rating, searching and retrieval. Textual semantic representations, such as tagging, labeling and annotation, are often important factors in the process of indexing any video, because of their user-friendly way of representing the semantics appropriate for search and retrieval. Automatic video annotation has received a great deal of attention from researchers working on video annotation. This study presents a Automatic video annotation to enhance the annotation accuracy and reduce the processing time in large-scale video data by utilizing algorithms. Automatic video annotation has become an important issue in visual sensor networks, due to the existence of a semantic gap. In these studies, we propose a system of CNN (Convolutional Neural Network) using You Only Look Once or YOLO model to detect objects in an video and generate representative keywords with accuracy.
INTRODUCTION
The notion of visual sensor networks is frequently reported as the convergence between the concepts of sensor networks and distributed smart cameras. As a result, the explosive growth of massive video data is afforded by both individuals and organizations users. Accordingly for the sake of the users to search the target video fast and accurately, in information retrieval realm there is a critical need for resolving the problem of how to organize, manage, and index these video data efficiently, thus video semantic annotation is the significant issue of the video indexing. Video semantic annotation, based on the video context, is giving the video the accurately semantic or conceptual “tag,” which leads to the mapping from the underlying characteristics to high-level semantic concept of the video and narrowing the “semantic gap”; also by employing these tags the video data managers are feasible to efficiently run the operations as accession, contractions, and so forth; moreover, to individual users it makes an approach to search and share videos; besides existing network video search engines like Google, YouTube, and Yahoo! Video mostly use the retrieval technology based on text as it shows its advantage at high speed and relatively maturity, and that the “tags” is an important part to constitute the video text information. However, manual tagging video losses in enormous workload and cost also fail in efficiency, with the drawback of high subjectivity. Hence it is necessary to bring the machine learning methods to approach automatic video annotation based on the analysis of the video content.
Commonly video annotation and retrieval ask for considerable relevance between the videos and the given concept, also called as correlation; nevertheless, that also emphasizes the “topicality” and “uniqueness” of the retrieval results . According to that, as fuzzy as the users input, one side for the video retrieval results is that it conveys more broad and diverse video semantics which leads to further catering for the requirement of the users on the other side the “topicality” of these “unique” videos also obtains the decent flux as encounter with magnanimous data, and thanks to the “non-redundant” retrieval results it enhances the users’ browsing efficiency as well.
Overview
The importance of automatic video annotation has increased with emerging huge mass of digital video data which is producing by video capturing devices and storing in the Internet and storage devices. Indexing, mining and retrieving relevant videos using textual queries is not trivial tasks since many videos have none or irrelevant annotations. Therefore, automatic video annotation has been proposed to act as a mediator in the applications of Content-Based Video Retrieval (CBVR) and video management.
This study is based on the machine learning technique to annotate video. Hence, the key idea of Automatic Video Annotation (AVA) is to construct the model(s) through automatic learning of semantic concept from many videos (even shots or key frames), then to utilize these concept model(s) for predicting appropriate annotation/label for any new video. Later, these annotated videos can be retrieved by textual queries.
Objective
Automatic annotation of video refers to the extraction of the information about video automatically. The objective of Automatic Video Annotation is to detect the objects using algorithms and to generate the keyword and accuracy of the object.
Purpose
The purpose of these application is to detect the objects with the use of YOLO model with CNN. This can be used in generating video in to frames and we can determine the accuracy of an object.
Scope
The scope of the project is the system on which the software is installed, i.e. the project works in the system where it is getting implemented. This project can be used as a base for creating similar applications which
- Can also detect objects in images, surveillance systems etc.,
- Can read a video and generate frame by frame.
Object Detection
Today, image resources are everywhere, and the number of available images can be overwhelming. Determining how to query, retrieve, and organize image information has become a popular research topic, and automatic image annotation is the key to text-based image retrieval rapidly and effectively. If the semantic images with annotations are not balanced among the training samples, the low-frequency labeling accuracy can be poor. In this study, a dual-channel convolution neural network (DCCNN) was designed to improve the accuracy of automatic labeling. The model integrates two Convolutional neural network (CNN) channels with different structures. One channel is used for training based on the low-frequency samples and increases the proportion of low-frequency samples in the model, and the other is used for training based on all training sets. We verified the proposed model on the Caltech-256, Pascal VOC 2007, and Pascal VOC 2012 standard datasets. On the Pascal VOC 2012 dataset, the proposed DCCNN model achieves an overall labeling accuracy of up to 93.4% after 100 training iterations: 8.9% higher than the CNN and 15% higher than the traditional method. A similar accuracy can be achieved by the CNN only after 2,500 training iterations. On the 50,000-image data set from Caltech-256 and Pascal VOC 2012, the performance of the DCCNN is relatively stable; it achieves an average labeling accuracy above 93%. In contrast, the CNN reaches an accuracy of only 91% even after extended training. Furthermore, the proposed DCCNN achieves a labeling accuracy for low-frequency words approximately 10% higher than that of the CNN, which further verifies the reliability of the proposed model in this study. CNN’s are mainly composed of a Convolutional layer, a pooled layer, and a fully connected layer. The Convolutional layer is a key part of the CNN. The function of this layer is to extract features from input images or feature maps. Each Convolutional layer can have multiple convolution kernels, which are used to obtain multiple feature maps.
The aim of object detection is to detect all instances of objects from a known class, such as people, cars or faces in an image. Generally, only a small number of instances of the object are present in the image, but there is a very large number of possible locations and scales at which they can occur and that need to somehow be explored. Each detection of the images
reported with some form of pose information. This is as simple as the location of the object, a location and scale, or the extent of the object defined in terms of a bounding box.
Bounding Box
In object detection, we not only need to identify all the objects of interest in the image, but also their positions. The positions are generally represented by a rectangular boundingbox.
In object detection, we usually use a bounding box to describe the target location. The bounding box is a rectangular box that can be determined by the Xx and Yy axis coordinates in the upper – left corner and Xx and Yy axis coordinates in the lower – right corner of the rectangle. We will define the bounding boxes of the dog and the cat in the image based on the coordinate information in an image. The origin of the coordinates in the the image is the upper left corner of the image and to the right and down are the positive directions of the Xx and Yy-axis, respectively. An example of a bicycle detection in an image that specifies the locations of certain parts

Anchor Boxes
Object detection algorithms usually sample a large number of regions in the input image, determine whether these regions contain objects of interest, and adjust the edges of the regions so as to predict the ground-truth bounding box of the target more accurately. Different models may use different region sampling methods. Here, we introduce one such method: it generates multiple bounding boxes with different sizes and aspect ratios while centering on each pixel. These bounding boxes are called anchor boxes.
Existing Algorithms
In Automatic video Annotation, there are algorithms that use the same encoder – decoder architecture. Some algorithms use InceptionV3 as encoder while some use custom neural networks. But most of the algorithms use traditional character to integer conversion and don’t use word embedding technique.
ResNet
To train the network model in a more effective manner, we herein adopt the same strategy as that used for DSSD (the performance of the residual network is better than that of the VGG network). The goal is to improve accuracy. We will also add a series of convolution feature layers at the end of the underlying network. These feature layers will gradually be reduced in size that allowed prediction of the detection results on multiple scales. When the input size is given as 300 and 320, although the ResNet–101 layer is deeper than the VGG–16 layer, it is experimentally known that it replaces the SSD’s underlying convolution network with a residual network, and it does not improve its accuracy but rather decreasesit.
Scale-Invariant Feature Transform(SIFT)
The SIFT method can robustly identify objects even among clutter and under partial occlusion because the SIFT feature descriptor is invariant to scale, orientation, and affine distortion.
Steps for feature information generation in SIFT algorithms:
- Scale – Space extrema detection
- Key point Localization
- Orientation Assignment
- Key point Descriptor
The Harris corner detector is used to extract features. In Scale-space extrema detection, the interest points (key points) are detected at distinctive locations in the image. In Key point localization, among key point candidates, distinctive key points are selected by comparing each pixel in the detected feature to its neighboring ones.
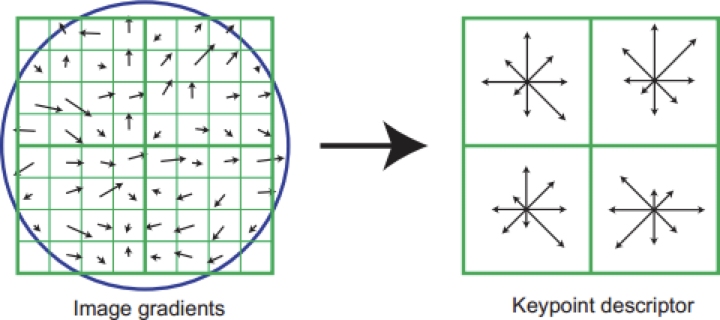
Figure 2.2 Scale-Invariant Feature Transmission (SIFT)
SSD (Single Shot Detector)
The SSD object detection composes of 2 parts:
- Extract feature maps
- Apply convolution filters to detect objects.
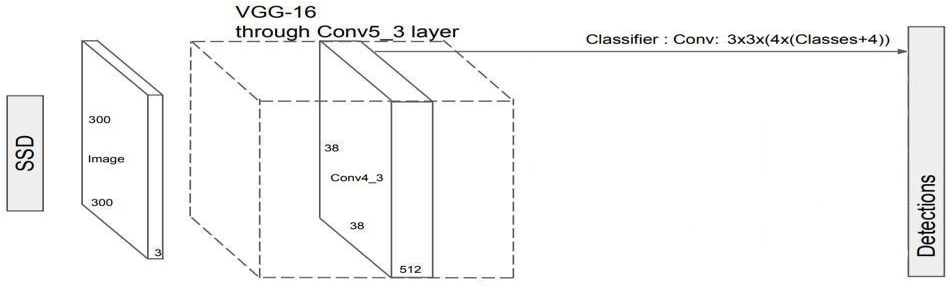
Figure 2.3 Single Shot Detector
By using SSD, we only need to take one single shot to detect multiple objects within the image, while regional proposal network (RPN) based approaches such as R – CNN series that need two shots, one for generating region proposals, one for detecting the object of each proposal. Thus, SSD is much faster compared with two-shot RPN – based approaches.
R – CNN
To circumvent the problem of selecting a huge number of regions, Ross Girshick proposed a method where we use the selective search for extract just 2000 regions from the image and he called them region proposals. Therefore, instead of trying to classify the huge number of regions, you can just work with 2000 regions. These 2000 region proposals are generated by using the selective search algorithm which is written below.
Selective Search:
- Generate the initial sub-segmentation, we generate many candidate regions
- Use the greedy algorithm to recursively combine similar regions into larger ones
- Use generated regions to produce the final candidate region proposals
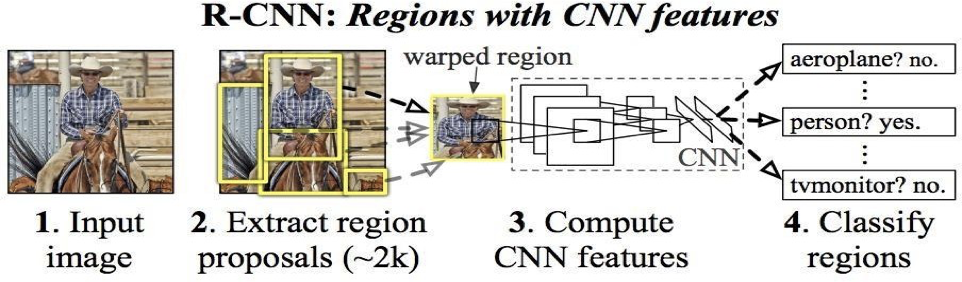
Figure 2.4 R – CNN: Regions with CNN Features
These 2000 candidate regions which are proposals are warped into a square and fed into a Convolutional neural network that produces a 4096-dimensional feature vector as output. The CNN plays a role of feature extractor and the output dense layer consists of the features extracted from the image and the extracted features are fed into an SVM for the classify the presence of the object within that candidate region proposal. In addition to predicting the presence of an object within the region proposals, the algorithm also predicts four values which are offset values for increasing the precision of the bounding box. For example, given the region proposal, the algorithm might have predicted the presence of a person but the face of that person within that region proposal could have been cut in half.
Therefore, the offset values which is given help in adjusting the bounding box of the region proposal.
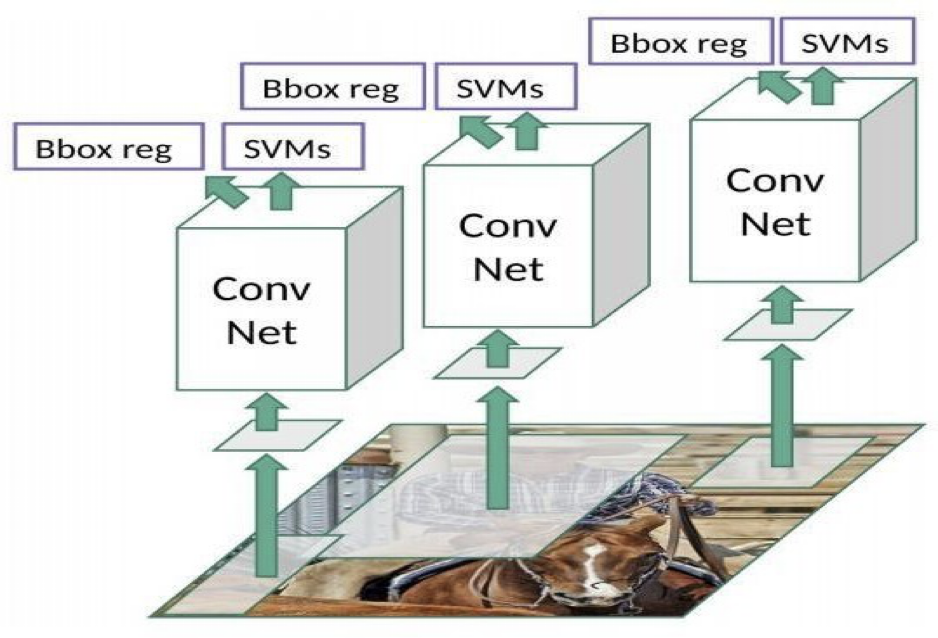
Figure 2.5 R – CNN
Fast R – CNN
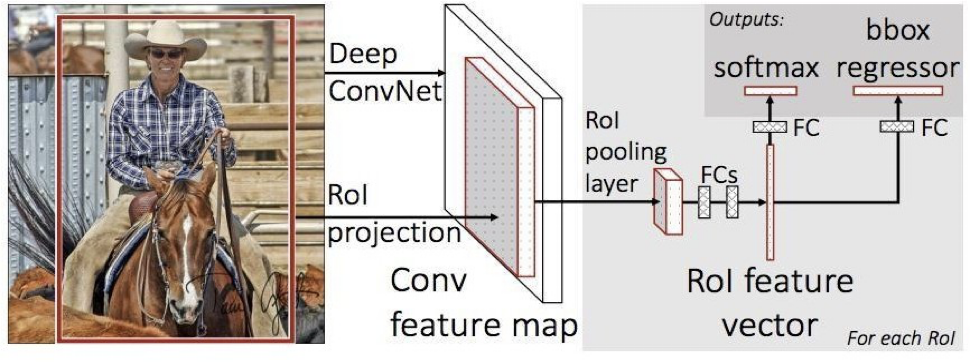
Figure 2.6 Fast R – CNN
The same author of the previous paper(R – CNN) solved some of the drawbacks of R- CNN to build a faster object detection algorithm and it was called Fast R – CNN. The approach is similar to the R – CNN algorithm. But, instead of feeding the region proposals to the CNN, we feed the input image to the CNN to generate a Convolutional feature map. From the Convolutional feature map, we can identify the region of the proposals and warp them into the squares and by using an RoI pooling layer we reshape them into the fixed size so that it can be fed into a fully connected layer. From the RoI feature vector, we can use a SoftMax layer to predict the class of the proposed region and also the offset values for the bounding box.
The reason “Fast R – CNN” is faster than R – CNN is because you don’t have to feed 2000 region proposals to the Convolutional neural network every time. Instead, the convolution operation is always done only once per image and a feature map is generated from it.
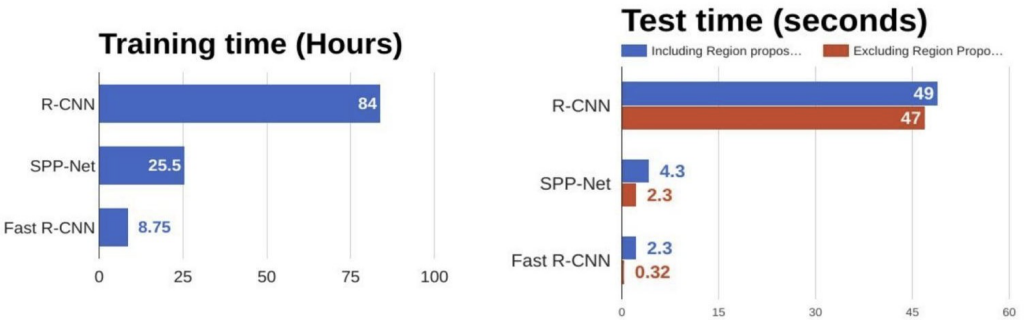
Figure 2.7 Comparison of object detection algorithms
From the above graphs, you can infer that Fast R – CNN is significantly faster in training and testing sessions over R – CNN. When you look at the performance of Fast R – CNN during testing time, including region proposals slows down the algorithm significantly when compared to not using region proposals. Therefore, the region which is proposals become bottlenecks in Fast R – CNN algorithm affecting its performance.
Faster R – CNN
Both above algorithms (R – CNN & Fast R – CNN) uses selective search to find out the region proposals. Selective search is the slow and time-consuming process which affect the performance of the network. Like Fast R – CNN, the image is provided as an input to a Convolutional network which provides a Convolutional feature map. Instead of using the selective search algorithm for the feature map to identify the region proposals, a separate network is used to predict the region proposals. The predicted the region which is proposals are then reshaped using an RoI pooling layer which is used to classify the image within the proposed region and predict the offset values for the bounding boxes.
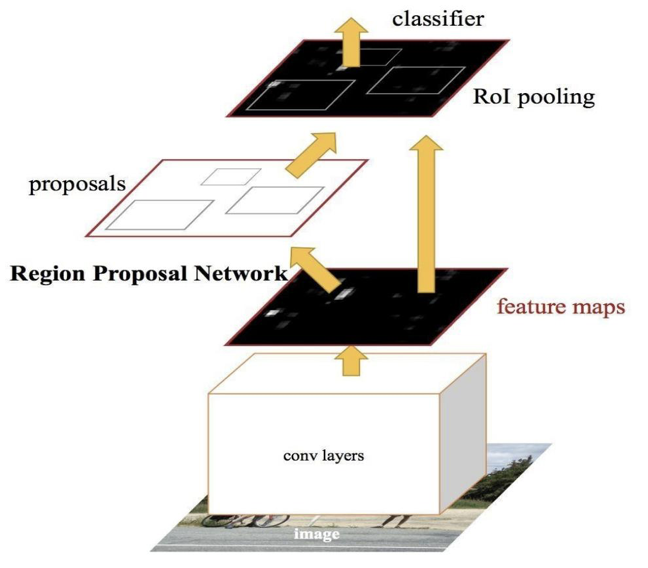
Figure 2.8 Faster R – CNN
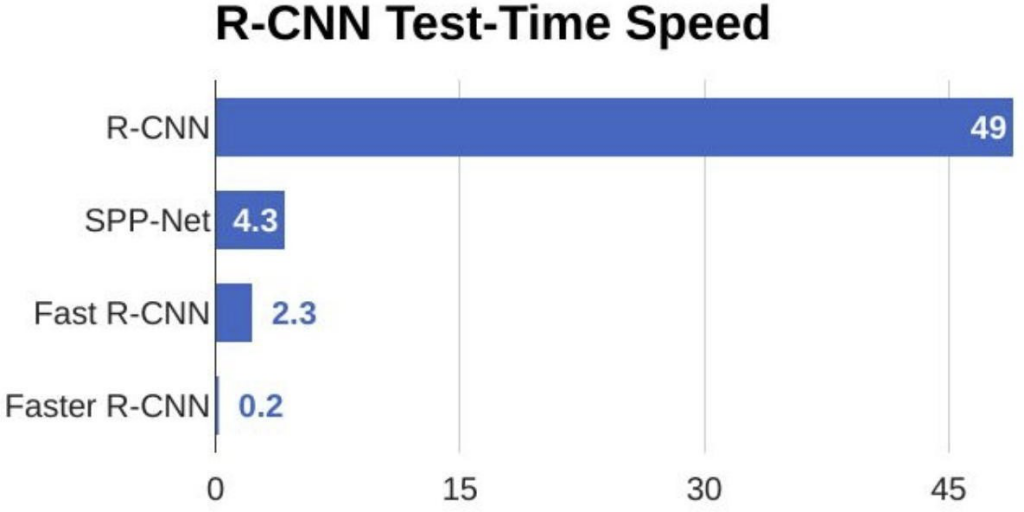
Figure 2.9 Comparison of test-time speed of object detection algorithms
From the above graph, you can see that Faster R – CNN is much faster than it’s predecessors. Therefore, it can even be used for real-time object detection.
MANet
Target detection is fundamental challenging problem for long time and has been a hotspot in the area of computer vision for many years. The purpose and objective of target detection is, to determine if any instances of a specified category of objects exist in an image. If there is an object to be detected in a specific image, target detection return the spatial positions and the spatial extent of the instances of the objects (based on the use a bounding box, for example). As one of cornerstones of image understanding and computer vision, target and object detection forms the basis for more complex and higher-level visual tasks, such as object tracking, image capture, instance segmentation, and others. Target detection is also widely used in areas such as artificial intelligence and information technology, including machine vision, automatic driving vehicles, and human–computer interaction. In recent times, the method automatic learning of represented features from data based on deep learning has effectively improved performance of target detection. Neural networks are foundation of deep learning. Therefore, design of better neural networks has become an key issue toward improvement of target detection algorithms and performance.
Recently developed object detectors that has been based on Convolutional neural networks (CNN) has been classified in two types : The first is two-stage detector type, such as Region-Based CNN (R–CNN), Region-Based Full Convolutional Networks (R–FCN), and Feature Pyramid Network (FPN), and the other is single-stage detector, such as the You Only Look Once (YOLO), Single-shot detector (SSD), and the Retina Net. The former type generates an series of candidate frames as samples of data , and then classifies the samples based on a CNN; the latter type do not generate candidate frames but directly converts the object frame positioning problem into a regression processing problem. To maintain real time speeds without sacrificing precision in various object detectors described above, Liu et al proposed the SSD which is faster than YOLO and has a comparable accuracy to that of the most advanced region- based target detectors.
Proposed Algorithm
You only look once (YOLO) at an image to predict what objects are present and where they are present using a single Convolutional network. YOLO predicts multiple bounding boxes and class probabilities for those boxes. This application will use trained weights from yolo v3 and then predict the bounding boxes and class probabilities using keras library
To overcome the drawbacks of the existing algorithms, the proposed algorithm has been evolved. In the proposed algorithm, we use CNN (convolution neural network) and You Only Look Once or YOLO Model to detect the objects in the video. We also generate the semantic tag of object with accuracy.
CNN, predicts the object region based on the feature maps of the different convolution layers, and outputs discretized multiscale and multi proportional default box coordinates. The convolution kernel predicts frame coordinates compensation of a series of candidate frames and the confidence of each category. The local feature maps of multiscale area are used to obtain results for each position in the entire image. This maintains the fast characteristics of YOLO algorithm and also ensures that the frame positioning effect is similar to that is induced by the CNN.
Advantages of Proposed Algorithm
- It is reliable.
- Works on huge amounts of data.
- Very effective.
- Very fast.